AI First
ContentGrid is AI first by design. The fact that we have a strong metamodel underlying the organisation of your documents, is a natural gift to machine learning and the transformer model. The contentgrid metamodel and AI are two sides of a coin: If you organise your documents according to strong semantic models (metamodel), AI will do a great job classifying those documents automatically and to create relationships between the document and the entities that are related to it.
In the design of contentgrid apps, we seek to eliminate (or facilitate) all manual interactions, from data classification to information retrieval. Where possible, the classification of a document is driven by an AI engine, the meta-data are suggested, and the related entities are identified and proposed to the user.

The AI First building blocks
Why is contentgid a superior foundation to apply AI on your documents?
1. Almost all documents contain all information required to be classified, if that information builds upon the main topics and entities the document already contains . (“The intelligence is already inside the document”).
2. Extracting entities that are relevant to a document can be trained and improved. It is a classical discipline in AI.
3. When putting documents in folders, you have to use previous, imperfect folders structures to train your AI model.
4. The metamodel of contentgrid allows for multiplicity : a document can be related to one or more contracts, to one or more customers. There is no way a foldering structure can model this properly.
5. While transformers are our most import trick of the trade (Hugging Face, ChatGPT, local models), we can leverage vector search as well, and leverage similarity between new and existing documents to improve automatic classification.
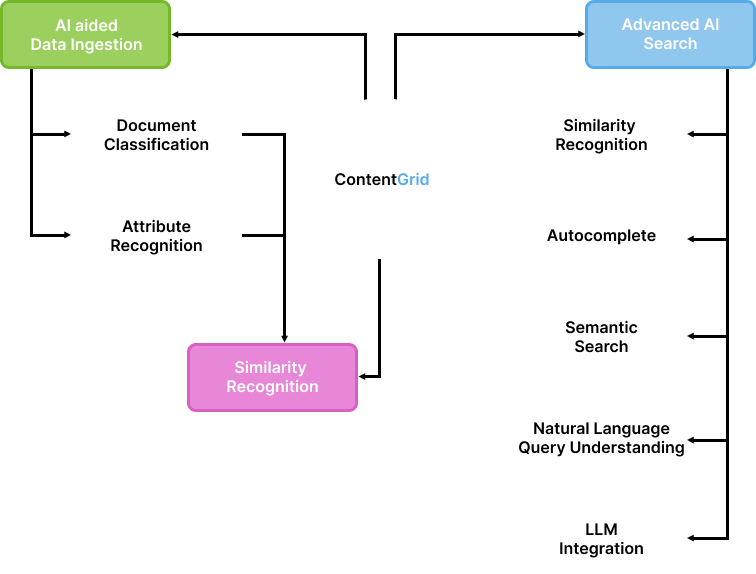
Document Classification
With document classification incoming documents are automatically routed to the correct document type. This allows users to ingest a heterogeneous set of documents into the correct type, avoiding the manual labor. Additionally, document classifiers can verify the existing classification of your document repository and find incorrectly placed documents.


Attribute Recognition
Attribute recognition automatically recognizes metadata from within the content of a document. For this task state of the art models (such as Transformers) are trained on your enterprise content, discovering the underlying patterns. Attribute recognition simplifies data ingestion and corrects missing metadata for documents within your repository.
Similarity Recognition
Document embeddings capture the semantic meaning of content. The resulting document embeddings (or document vectors) can be used in vector search to find similar documents, providing users with related items to the document they are currently reading.


Autocomplete
Autocomplete enhances the user's document search experience by anticipating their needs as they type. While the user is typing, attribute predictors are working in the background predicting what type of attribute the user is looking for. This predictive assistance is so swift that users can click on the suggested attribute before they even complete typing the word or phrase, instantly initiating the search.
Semantic Search
Semantic Search revolutionizes the way we find information by adopting a document-vector-based approach, leveraging document embeddings. This cutting-edge technology empowers users to use broader and more general search terms, enabling more accurate and contextually relevant search results


Natural Language Query Understanding
Natural Language Query Understanding is the foundation of modern human-computer interactions. it allows you to execute searches in ContentGrid in plain, natural language, eliminating the need for rigid, predefined search languages/commands making search more intuitive and simple.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is a hybrid approach that combines elements of both retrieval-based and generation-based natural language processing models (LLMs). Firstly, the user submits a question (similar to a chatGPT question). Then relevant documents to the question are retrieved from within the repository. Then the question along with the relevant documents are sent to a GPT model which can enhance the quality and accuracy of its generated responses.

Discover how it works
In today's digital era, the importance of effectively managing, retrieving, and storing information cannot be overstated. Whether you are a business looking to optimize your workflows, a team trying to streamline content management, or an individual striving for efficient document control, ContentGid is designed with you in mind.
Discover how ContentGid leverages cutting-edge technology to provide a seamless and intuitive content management experience.
