
Handling large datasets efficiently is a core challenge for any system dealing with big data. At ContentGrid, we recently conducted performance testing on our platform using a dataset of 500 million documents, focusing on query response times and throughput under varying conditions. Our tests aimed to evaluate how well ContentGrid manages high concurrency query workloads, ensuring a seamless experience for users. Here’s a deep dive into our testing methodology, key findings, and the implications for optimizing query performance.
Optimizing ContentGrid Query Performance: Insights from Our 500M Docs Test
Test Setup: Understanding the Parameters
Our performance testing focused on a data model comprising two entities: Supplier and Invoices. Queries were designed to search for invoices linked to specific suppliers, using the "payBefore" field to filter results within a given date range. These queries returned up to 20 results per request and were tested in three scenarios: unsorted, sorted in ascending order by "payBefore", and sorted in descending order by "payBefore".
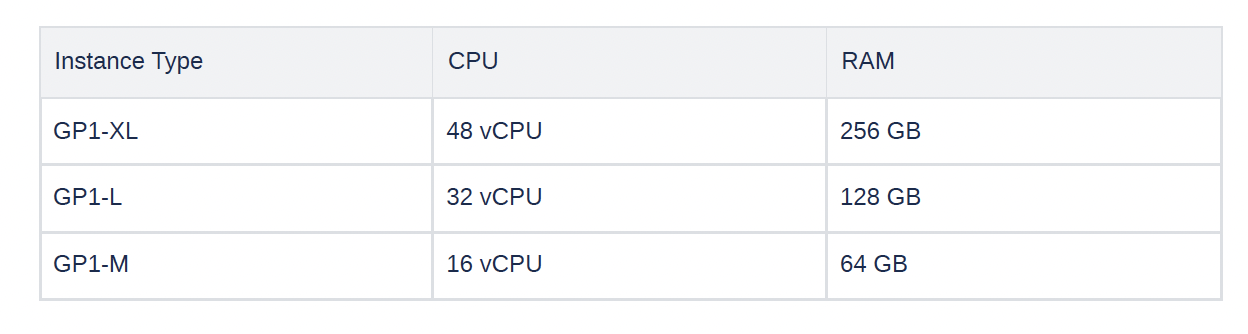
To evaluate system performance, we used three instance types with varying processing power and memory sizes.
Each instance was tested with two concurrency levels—25 and 50—to assess how well the system manages varying numbers of simultaneous queries.
The database for this testing was PostgreSQL 17, installed using the standard Docker image to ensure consistency. We also tuned PostgreSQL's configuration to match the available CPU and memory of each instance, optimizing settings like max connections, work memory, and cache size to leverage the full potential of the hardware.
Our API server, responsible for managing interactions between the application and the database, was standardized across all tests, featuring 8 vCPU and 6 GB of RAM. This consistency ensured that any observed differences in performance were due to the database configurations and hardware resources rather than the API server capabilities.
This testing approach allowed us to analyze how different instance types and concurrency levels impact the query performance, providing insights into the scalability and efficiency of ContentGrid under various conditions.
Mixed Counting Strategy: Exact vs. Estimated Counts
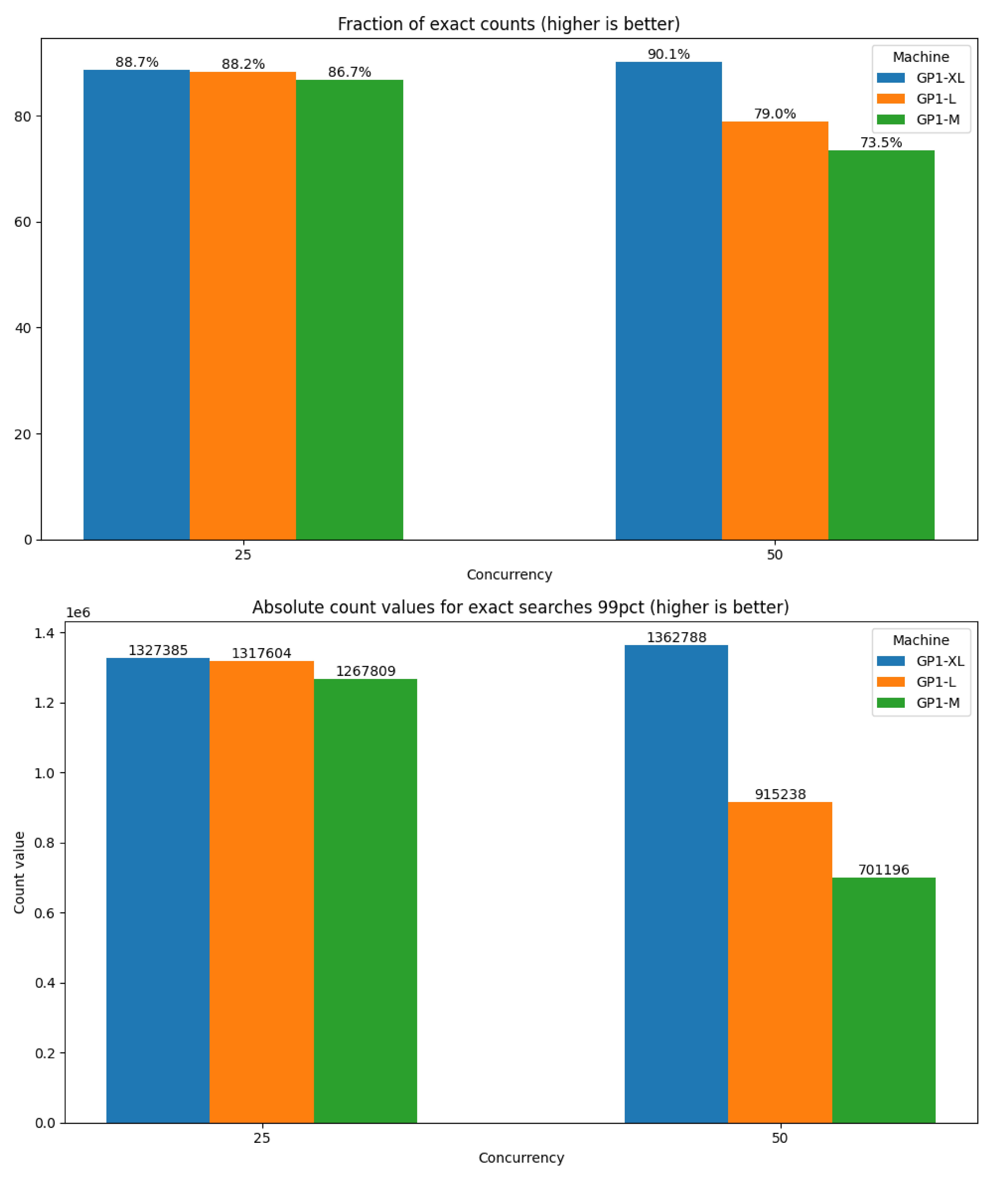
ContentGrid employs a mixed counting strategy to optimize query performance. The system first attempts to return an exact count of results, provided it can do so within 1 second . If the process takes longer, it switches to an estimated count , striking a balance between accuracy and speed. To better understand the impact of this approach, we analyzed response times for both exact and estimated counts. The graph below illustrates the proportion of requests that were processed with exact counts.
As the graph shows, higher concurrency levels lead to a decline in the percentage of exact counts. This indicates that fewer queries are completed with exact counts, as the system takes longer than 1 second to respond, triggering a shift to estimated counts. While this ensures a faster overall response, it reflects the increased load on the system as concurrency rises.
It's important to note that our tests involved queries with relatively large result counts. The highest 50th percentile exact count value recorded was just over 100,000. Considering that exact counts made up only about 90% of the responses, and that estimated count queries typically return even higher counts, the true median count (50th percentile) is likely higher than what we observed for exact counts alone.
To illustrate how large these result sets can be when maintaining exact counts—and how concurrency and hardware resources affect these numbers—the graph below shows the 99th percentile of exact count values.
As shown, the differences become significant with higher concurrency. Due to CPU saturation, exact count queries tend to time out more frequently on databases with fewer resources, resulting in a shift towards estimated counts. This highlights the impact of both machine capacity and concurrency levels on maintaining precise query counts under load.
Key Metrics: Throughput and Response Times
Throughput
Throughput measures the number of requests a system can process per second (req/s), reflecting its efficiency in handling workloads. It is closely tied to concurrency, or the number of simultaneous requests the system manages. Ideally, as concurrency increases, throughput should rise, allowing more requests to be processed at once. However, if system resources like CPU and memory reach their limits, throughput may level off or decrease as requests compete for resources. Finding the right balance between concurrency and resources is key to optimizing throughput.
At a concurrency level of 25, the throughput remained relatively stable across different instances.
With a concurrency of 50, throughput differences became more pronounced, with larger instances handling the load more effectively. For example, the GP1-XL-C50 showed a 153 req/s request throughput, significantly higher than the GP1-M-C50 at 101 req/s.
Response Times
Global response times showed variations, particularly at higher concurrency. The 99th percentile of response times (the time within which 99% of the requests are completed) was slightly higher for smaller instances when concurrency increased, suggesting they were more susceptible to load saturation.
Insights from the Results
Based on the results, we found that ContentGrid effectively manages high-concurrency query workloads, especially when using more powerful instances. Here are some key takeaways:
Scalability: ContentGrid scales well with increased hardware capacity. Larger instances with more vCPUs and RAM handled higher concurrency levels with better throughput and lower response times.
Response Time Optimization: For applications where precise counts are crucial, focusing on exact count optimizations can provide significant performance improvements. However, in scenarios where response speed is more important than count precision, allowing for estimated counts can ensure a smoother user experience.
Concurrency Handling: At lower concurrency levels, even smaller instances performed well. This suggests that organizations with moderate traffic can achieve cost savings without sacrificing user experience. However, for heavy workloads, investing in larger setups like the GP1-XL series ensures the system remains responsive.

Conclusion: A Balance of Performance and Cost
Our performance tests underscore the ability of ContentGrid to deliver robust query performance, even when dealing with large datasets and high request volumes. By leveraging the right database configurations and hardware setups, organizations can achieve a balance between performance and cost. For businesses dealing with extensive data operations, tuning concurrency levels and optimizing database configurations based on specific needs can result in significant gains.
As data continues to grow, so too will the need for efficient query performance. ContentGrid remains committed to evolving and optimizing our platform, ensuring that users can manage their data at scale without compromising on speed or accuracy.